- I've finally completed my PhD Thesis! - I say.
- And what is your Thesis about? - they answer.
And there comes the difficult part... because sometimes when i get into the details, the general idea is lost.
Therefore, here I'm trying to give an informal overview on what is my Thesis about.
The thesis proposes a way to provide an insight to the commands that guides the robot so the robot could make better and informed decisions on how to apply them.
Also, by involving the robot as an active element of the decision making process, the robot designer is freed from having to manually adjust how all the commands that should be mixed.
The proposed method is applied to the navigation of several of robots that are then able to navigate as independent individuals, as a clustered group or in different formation shapes, always using the same decision making process.
Along the thesis there have been done a lot of tests, mostly in simulation, but also a group of (small) real robots have been build and the results from simulation have been validated by the experiments with real robots (and here are some videos).
This Thesis is focused in the reactive navigation of robots controlled through behaviour blending.
It is proposed a way to systematically provide some level of knowledge about the context in which each action will be applied as a way to improve the blending process of the multiple actions to be considered at the same time.
The use of the context information associated with each action allow to simplify the tune of the behaviour blending process for while it permits a more complex action interaction, thus allowing the designer to focus in the behaviours and relieving the tuning process.
Along the Thesis a way to describe the actions and their associated context is proposed along with a method to combine them focused in the robot navigation trough an unknown scenario.
Also, an original use of the virtual potential fields is proposed and used for the world description.
The generality of the proposed solution is studied through the use of the same method and blending function along four different scenarios:
- Single robot navigation among obstacles.
- Multiple, independent robots among obstacles.
- Multiple robots moving as a group among obstacles.
- Multiple robots moving in formation –decentralized, anonymous and flexible– among obstacles.
Because of its higher complexity, the formation navigation scenario have been studied deeply through simulation for different formation shapes –line, column, circle, wedge and several point formations– and several formation sizes –from 3 to 30 robots–.
The main indicators studied through simulation –robot distance to formation, robot dispersion around the formation and time to reach a stable formation– have been also studied for its validation using real robots in a subset of the scenarios –line, column, circle and wedge formations with 3 to 6 robots–
The obtained results –validation of the simulations and linearity with the number of robots along the formation indicators– points to a proper distribution of the scenario complexity among the robots into it, the predictability of the obtained solutions and the feasibility of extrapolating the results for scenarios not yet studied.
The work line from this Thesis is open to a deeper study of the considered contexts observed in the description/decision process, the combination or the extension of the method to work with high level path planners or machine learning methods, and it also opens the application of the proposed methodology to fields of robotics different from navigation.
Introduction: Motivation, the beginning
This thesis was the result of a previous collaboration with my current supervisors where I learnt how-to and build several autonomous robots (I look for it, I get to know them by asking a faculty teacher about with whom and how can I learn about robots).
Those initial robots behave independently and individually, for them anything around them was some kind of obstacle or something which they have no relation with. All the things around them were just something in their way to the goal, no more than that.
From those initial robots I learn two main things -related to this thesis-: the first one was that I will be able to do much cooler things if I can have several robots working together; the second thing was that the process of designing a robot to do an specific task is mostly the same all the time, no mater what the task is about.
But also I experience -while designing a good number of 'specific tasks'- that the process of adjusting the little details of a behaviour, while being essentially the same from one design to other, takes a lot of time ... a lot of repetitive effort.
This tweaking with the robot was fun the first dozen of times... but afterwards it was boring. I want to focus on the robot final behaviours, the higher level specific tasks where the challenge was, I already know how to tweak with the details!
Then, when i put together those two ideas this Thesis born because ...
"I want to use several robots at the same time" + "When building a single robot, i spent more time in a unrewarding and repetitive effort than with the really interesting parts" = "I'm going to throw it all out of the window"
So the Thesis begins with the question: "How can i develop a group of robots that work together in a easy way?"
Introduction: Learning about
After all those thoughts I began to read about coordination and cooperation in robotics to find that there are a huge amount of work into that field, but each of them focused in different aspects : how to handle communication networks, how to put knowledge in common, how to reach to a decision and share it between the robots, etc.
I was interested in a lower level of the coordination/cooperation schemes, the actual navigation process, so I focused in group and formation navigation which deal on how to move the robot and leaves open to the next layer the deeper planning.
Actually formation navigation is also quite a big field, since depending on the kind of structure that you want to build you have a lot of choices and restriction.
But i don't want to restrict to a single scheme, so i try to leave as much choices open as i can.
Introduction: Main elements on robot navigation
When you work with robot navigation the very first question you need is: "Will I have all the relevant information just at the beginning or will I discover new things as I move around?"
If you are in the first situation, you have all the information just at the beginning (and all the time), your scenario is static or you know exactly how it will evolve so you will probably focus on path feasibility, optimization, etc. You have all the data: get the best out of it.
If you are in the second situation, you don't have all the information, you should focus on decision making, learning, adapting, etc because you have limited sensing and/or your scenario changes all the time . You don't know what is coming next: be careful and survive (and think fast, because it can hit you)
I put myself in the second case: My robots can only sense the things that are near them and they assume that they can change at any time.
Also they don't have memory or project their thoughts to the future, they work only with the immediately available data and only take decisions about their immediate next move.
This kind of setup is called reactive behaviour.
It can be said that this kind of robots guide themselves by pure instinct, but instinct is usually guided by some inner knowledge of how a situation will evolve based on how it is now.
Robots do not have this kind of knowledge but the developer of the robot can (should) provide it ( except if you focus your work on the learning process).
One of the most common ways to represent the knowledge that the robot will use is called 'Behavioural description', which is based on the 'Motor Schema' from R.C. Arkin.
This knowledge description consists in providing a collection of Actions that should be taken in certain Situations, where ideally each Situation-Action covers a specific element of the world and the Intelligence of the robots emerges from the combination of several Situation-Actions.
An example:
A situation -At any time- states that a robot must -Move in the goal direction-, and second situation -When the robot is close to an obstacle- states that the robot must -Move away from the obstacle-.
Using these two Situation-Action behaviours, an smart robot will move straight toward the goal and when it finds a obstacle in the way it will move around the obstacle.
The tricky part with any knowledge description that merges several things together to take the final decision is the merging process. It is quite common that when two situations are true at the same time, the associated actions are incompatible.

|
| Which one should be followed ? |
In those cases some kind of arbitration between the situations is needed, because the robot can only do one thing, but which?
To solve this kind of dilemma there are two main approaches: Hierarchical relations between situations or Weighted Consensus were each situation have a different relevance.
- When talking about Hierarchical arbitration probably, the most relevant work is probably the Sumsumption Architecture by R.A Brooks. Following this strategy the behaviour -When the robot is close to an obstacle: move away from the obstacle- will have precedence over the behaviour -At any time : Move in the goal direction-, so when the two situations are true at the same time, the second one will be simply ignored if it oppose the first one.
- Using the Weighted Consensus each behaviour will have an associated weight and the final direction of the robot will be obtained through a weighted mean off all the active situations. In the Weighted Consensus approach, the behaviour that takes care of the obstacle will have a grater weight than the behaviour that guides the robot toward the goal, so when the two of them were active at the same time the result will be a movement mainly away from the obstacle but slightly toward the goal.
This is a very, very common approach, and the Virtual Potential Fields from O. Khatib and derivative works can be considered as Weighted Consensus.
Proposal: Toward simplification
As it can be seen, behavioural description can be quite powerful, but the tricky part is the arbitration of the different behaviours which can be active at the same time and which actions are not always compatible.
So, if we can simplify this arbitration process we will simplify the overall design effort.
The robot designer knows how the different actions are related, and this knowledge is the one that establishes the arbitration function. But with the classic arbitration methods all the effort of the arbitration falls on the designer.
In this Thesis, I aim to release some parts of that effort from the designer and leave it to the robot. To do that I change how the designer states the actions related to each situation.
In a classical behavioural description the designer states the specific action that it want the robot to take in a given situation.
Later, in the arbitration function, and according to the nature of each action, it establishes how the different actions can be blended.
The 'nature' of the action actually represents the implications of the action in the overall scenario: the final task, the restrictions, etc.
In a classical approach, the designer will tell the robot to move in a specific direction because it helps the robot to progress in its task or it moves the robot away from the danger or it avoids the robot to move into a dead end under the criteria of a given behaviour, but the reason for that action is not transmitted to the robot.This means that it is the task of the designer to explicitly sort all the possible interactions among the different actions, which can be a tough task, since the number of interactions grows quite quickly with the number of considered actions.
Afterwards, in the arbitration function design, the understanding -by the designer- of the role of each individual action will be the key element on how the actions must relate between them and what is the precedence among them.
It also implies that any change in any action of any behaviour will involve check again all the interactions related to that action.

|
| The classical approach does not provide enough information to the robot to make it's own decision, it all depends on the designer |
Instead of using this classic approach, along this Thesis the designer do not states the action intended for the robots associated with a given situation, but it states the consequences of taking the different actions.
And the arbitration process will be now a function that states how to mix the different consequences to provide a proper action for the robot.
In this Thesis, the designer, under the perspective of a given behaviour, will not state the desired movement direction for the robot, but it will state the implications of moving in the different directions: which ones will help the robot to get away from a problem, which ones will help the robot to progress in its task,etc.This means that the designer have to provide a better description for the individual behaviours, but the arbitration function is now easier to set, since the evaluation of the different implications will be now a general guideline on how to minimize the bad implications and while maximizing the best ones.
Afterwards, the arbitration function will be build so in evaluates together the implications of from all the behaviours and find a movement direction that maximizes the positive implications while keeping away of the negative implications.
This also implies that not only a change on an action will not affect the arbitration function -the guidelines remain the same- but that the arbitration function can be used again for other tasks that could be described trough the same set of implications. -"Drive around safely" is valid for an individual robot patrolling a perimeter, a robot moving in a group or a robot looking to build a formation-

|
| The proposed approach is to provide just that extra bit of information that allow the robot to evaluate the options by itself -following a general rules from the designer- |
The expected results of such approach is that the designer will no longer need to expend so much time balancing the different actions so their interactions work properly, but instead, by providing more details of the individual situations, the general guidelines of the new arbitration function will do the balancing on the fly.
In this way the designer will be able to focus on richer behaviour descriptions and a more complex collection of behaviours, since it will be the robot who will balance them.
Also, the re-usability of the new arbitration function will made much easier to have a robot able of multiple tasks -all using the same arbitration function- and to develop multiple robots with different tasks which work together -all constrained by the same general guidelines-
Implementation: Elements
To transform the general idea of the proposal into a practical thing three main elements are needed:
- Decide on which consequences will be needed. Because the arbitration function will only be able to balance the kin of consequences that it knows.
- Estate how to describe the consequences. This is needed for the developer to be able to put the data in a way which can be handled by the arbitration function.
- Describe the world to the robot. So it can evaluate the situations and apply the consequences stated by the developer. This description also establish which kind of data the developer can use to describe the consequences and situations.
- Considered Consequences
Since the application frame of the Thesis is to drive multiple robot around, the general idea on the kind of arbitration applied will be: "Drive around in a safe way to complete your task".
Therefore it have been considered enough two kind of consequences, or consequent actions, to properly describe this general guideline:
- Movements that helps the robot to progress on its task -> Recommendations
- Movements that may harm or prevent the robot from completing its task -> Restrictions

|
| Recommendation toward the goal (green) and Restriction toward the wall (red) |
- Consequence Description
Describing the consequences of moving in the different directions available to the robot is far from a discrete thing. A single direction may be the best one to take -the one that result in a higher progress on the task- but most probably most of the surrounding directions will also imply a progress in the task, however lower than the best one. Also the direction that points to the center of an obstacle will represent a possible harm, but also all the directions that points toward any point of the obstacle, and even those which points in directions close to the obstacle should be also, in a lower amount, considered as potentially harmful.
For these reasons, to describe the different consequent actions, Recommendations and Restrictions, a modified Gaussian function have been used. This function allows the developer to state the value of the action maximum intensity, the region of maximum intensity and the size of the tails where the intensity falls from the maximum intensity to zero.

|
| Extended Gaussian function as the basic descriptive element |
- World Description
The evaluation of the consequences of the robot actions may be analyzed over each one of the elements present on the world, however, as the number of elements grow, the effort of this evaluation will also grow, but just a few of them will be truly relevant in the final action.
To reduce this effort to the minimum, but still proper, analysis the elements in the world must be arranged so only the relevant ones are actually analyzed.
To do that, in this Thesis, a variation of the Virtual Potential Fields methods have been applied.
The elements of the world are classified based on the information needed to solve the task. A virtual potential field is then build using all the elements of a same group, where the field function is tuned to maximize the interesting characteristic of that specific group.
The variation on the classic Virtual Potential Field methods is that each group is considered independently and a virtual field is build for each group, however the fields from the different group are not mixed, they are kept apart and they do not build a final unified virtual field.
The advantage is that in this way the amount of specific information available to state the actions can be tuned to each task, and there is no need to balance the relevance of the different groups in their final mix. Also a same element can act as a source of different fields based on different needs of information.
An Example:
When considering a collection of robots that must act as a group we will need information about the robots to avoid collisions between them but we will also need information about the robots to know the characteristics of the group.Each of the potentials will provide to the robot the direction (through the gradient) and the distance (using the inverse function of the field) and those values are the ones which are actually evaluated and used when describing the consequences.
Using multiple potentials, we will build a potential field which highlights the nearer robots to avoid the collisions and a second potential field which highlight the centroid of the robots to characterize the group.
By keeping these two potentials apart we can take better decisions, because we have more information than if we add the two potentials together.

|
| Describing the world trough multiple independent Virtual Potential Fields |
Implementation: Context Arbitration Function
Since the designer will provide to the robot a collection of consequences and its relevance based on the different situations considered, the arbitration function will work over the full set of consequences. Therefore it will be aware of the full context of the robot at the time of taking the decision on the final action.
Focusing the arbitration function on the general idea of "Drive around in a safe way to complete your task" the arbitration is done through several steps which gather and compare the Recommendations and the Restrictions.
- All the Recommendations are put together in a single recommendation map. To put together them, they are added, so the most recommended direction will be the one with higher recommendation intensity and with the higher number of behaviours recommending it.
- All the Restrictions are put together in a single restriction map. This time, the restrictions are overlaid, so at the end the restriction level at each direction will be the maximum restriction stated by any of the behaviours considered.
- A viability map is build. This map represents the directions that are recommended and not restricted. It is build by a product of the recommendation value and the restriction value for each direction.
- A safe turn map is also build, because the considered robots move like cars, -they cannot move sidewards, they need to turn with a given turn radius-. This map analyzes the amount of restricted space that must be transversed to turn from the current robot direction to a new one. The cross of restricted directions results in a exponential drop on the safety level.
- A turning cost map is also build to reflect the impact on changing the robot trajectory. A little change on the robot heading will result in a low cost, while a higher change results in a higher cost.
- A final manoeuvre valoration map is build to put together the results from the viability map, the safety map and the turning cost.
At that moment the robot will began to turn to reach the final desired direction but, since the system is reactive and all these evaluation is done continuously, the desired direction will keep changing as the robot moves and its surroundings changes. This is the way in which the robot is able to always keep adapting to the world.
Testing the method
Since one of the objectives is to develop a methodology flexible enough so it can be used in several cases, and one of the goals is to handle several robots together, to test the proposed method several scenarios have been studied.
Four different task have been studied and implemented using the same method: describing the behaviours through the same consequent actions, Recommendations and Restrictions, and in the four cases exactly the same arbitration function have been used.
- A single robot aiming for a goal in a world with obstacles
- Several independent robots aiming for several different goals in a world with obstacles
- Several robots, behaving as a group, aiming for a goal in a world with obstacles
- Several robots which have to arrange themselves in a given formation shape and move, as a formation, in a given direction in a world with obstacles.
- Single Robot
This task is the simplest one, but is the base case where other methods are tested and sometimes failed.. but not this time.
This task needs to consider two things: the goal and the obstacles, so two virtual potential fields are used, one for each.
To design this task the robot evaluates two situations and with four consequent actions.
- The first situation is: At any time(actually not a situation to be evaluated), and it have a single consequent action associated that is to recommend the direction of the goal -and the pi/2 region to its sides with lesser relevance-
- The second situation is Near an obstacle and it have three associated consequent actions: A restriction on the directions which covers the obstacle -with a safety region pi/12 for the tails- and two recommendations, each one pointing to the sides of the obstacle, so the robot will easily clear the obstacle.
The intensity of this three consequent actions is set to be zero when the obstacle if far enough and to grow as the robot gets closer to the obstacle.
The great advantage is that there have been no need to fine tune the parameters of the actions or the situation indicators.
- Multiple Independent Robots
This task is also simple, but is the classic potential fields methods usually have a difficult times to solve it.
In this task three elements have to be considered: the goal, the obstacles and the other robots, so three different potential fields have been used.
This task share with the previous one the desired behaviour of the robot for the goal and the obstacles, so the situations and the actions used in the single robot task have been also used in this task without any modification.
However the introduction of the other robots needs to be handled. For this a new situation -Near to other robot have been added, and three actions: a restriction to move in the other robot direction and two recommendations to move to the sides of the other robot.
Again the same Context Arbitration function is used to blend the different consequent situations into the desired movement of the robot.
- Robots as a Group
This task employs the same present in the Multiple Independent Robots case, but now we also need to know about the group. For this a fourth field, the group field, have been added. This group field is also build from the other robots positions, but now it is shaped so it points to the centroid of the robots. This can only be done because the different field are not mixed together.
For this task, the behaviours considered for the goal and the obstacles have been used again as it have been designed for the Single Robot case. The behaviour to avoid collisions with other robots used in the Multiple Independent Robots can also be used, however, since now the other robots will be moving with us, only the restriction to move in the other robots direction is employed, the recommendations to move around the other robots are no longer needed.
Related to keep the group together, a new set of behaviours are introduced, i.e. reduce the speed when the the robot is ahead of the group and already oriented to the goal, or to move diagonally to join the group when the robot is at a side.
Again the same Context Arbitration function is used to blend the different consequent situations into the desired movement of the robot.
- Robots in a Formation
Here a new element have to be considered, the formation structure. The considered formation is designed as an anonymous formation -any two robots can be swapped with no effect-, distributed -there is no external coordination, each robot makes its own decisions- and flexible -the robots do not belong to a specific point of the space, but to a region in which they can move-. The formation structure have been build as a potential field where the minimal region shapes the formation.
For this scenario, the same behaviours regarding the goal and obstacles as the ones used in the Single Robot case have been used, also the behaviour related to the collision avoidance of the Robt Group case have been employed.
To handle the formation gathering a dedicated set of behaviours and consequent actions have been used, i.e. a recommendation to move around the perimeter of the formation when the direct path toward the formation is already occupied by other robot.
Again the same Context Arbitration function is used to blend the different consequent situations into the desired movement of the robot.
To place the formation structure over the robots, each robot takes the other robots positions and iteratively adjust the formation field so it minimizes the mean potential for all the other robots.
Four main formation shapes have been studied: Line, Column, Circle and Wedge, also other formations such as a hexagonal cluster or a smile have been tested. On all these formations the arrangement process have been studied and different manoeuvres, obstacles and transitions between formations have been tested.
Tests.
These are only a few, around 8000 scenarios with nearly 90000 robots have been tested in simulation and 90 scenarios with nearly 400 robots have been tested in real.
|
Single Obstacle
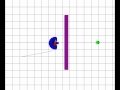
|
Multiple Obstacles

|
|
4 Robots

|
5 Robots in a jam

|
|
Group Vs. Wall

|
Group Vs. Wedge
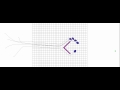
|
Group Vs. Multiple Obstacles

|
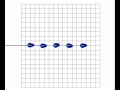
7 in Circle

|
7 in a Column

|
7 in Line

|
7 in Wedge

|
|
|
9 in Diamond

|
9 in Smile

|
|
11 in Circle

|
11 in Column

|
11 in Line

|
11 in Wedge

|
20 in Circle

|
20 in Column

|
20 in Line

|
20 in Wedge

|
0.01 rad / s

|
0.05 rad / s

|
0.1 rad / s

|
1 rad / s

|
0.5 rad / s

|
1 rad / s

|
1 rad / s

|
Column Vs Wall

|
Line Vs Wall

|
Wedge vs Wall

|
Circle vs Wall

|
Column Vs. Column

|
Row vs. Column

|
Circle vs Column

|
Formations with Real Robots:
[The white lines are not the actual formation line, just an indication ... I do not thought on logging the time-stamp from the video frames so i cannot sync experimental data with the video frames :( ]
3 in Circle

|
3 in Column

|
3 in Line

|
3 in Wedge

|
4 in Circle

|
4 in Column

|
4 in Line

|
4 in Wedge

|
5 in Circle

|
5 in Column

|
5 in Line

|
5 in Wedge

|
6 in Circle

|
6 in Column

|
6 in Line

|
6 in Wedge

|
The first impression, looking at the simulation and the reals tests is that the robots behave correctly. But to really measure the results some formal analysis must be done.
The formal study have been done only with the Robots in Formation task, since it is the most complex one it will provide the richest data but also the pronest to fail.
An extensive study have been done using four formation shapes : Line, Column, Circle and Wedge and 10 formations sizes, from 3 to 30 robots in simulation and from 3 to 6 robots with the real ones.
To evaluate the results and be able to compare the different formation tests three indicators have been studied:
- The distance between each robot and the formation, which indicates the evolution of the robot as an individual.
- The dispersion of the robots around the formation, which indicates the evolution of the robots as a group.
- The time needed to reach a stable formation, which indicates the performance of all the system.
The results have been partially a surprise, it was expected a certain uniformity of those parameters but not so much. However, the shape of those parameters along all the tests, have shown the same behaviour and a greater correlation than expected.
The distance from the robot to the formation and the dispersion of the robots around the formation evolves as a exponential decay function, and the time needed to reach a stable formation shows a Poisson distribution.
This is good, it resembles a natural process and it was expected to get results like this.
But, when those functions are parametrized:
- The decay constant of the robot-formation distance and the dispersion shows a strong linearity with the number of robots of in the formation.
- The expected robot-formation distance and dispersion at t=infinity is within the same range and flat for all the formation sizes.
- The mean time needed to reach an stable formation shows a strong linearity with amount of robots in the formation.
- The real robots shows the same tendency in their indicators as the simulated robots.
- The results of the parametrization of the indicators for the real robots tests falls within the same region of the parameters obtained in simulation.

|

|
| Exponential decay parameters for the different cases. | Mean time needed to reach a stable formation for the different cases. |

|

|
| Exponential decay parameters, Real tests vs. Simulations | Stable Formation Time distribution, Real tests vs. Simulations |
Looking to this results we can say that the method seems to work pretty good.
Also the linear relation between the indicator' parameters and the number of robots, where the specific formation shape is only a minor factor, indicates that we could have properly good predictions on how other numbers of robots which have not been tested will behave and even how other kinds of shapes will also behave.
The regularity of the evolution of the indicators also allows us to extract useful information on how a specific test will evolve and to identify problematic situations -like a jam or a hardware problem in a robot- since the indicators will drift out of the expected.
So, at the end, all the initial ideas seems to work good and the obtained results have been very good.
The initial objective of simplifying the process of developing a robot or a group of robots have been reasonably fulfilled. The experience of building the different test cases -once all the system was fully deployed- have been quite easier when compared with my previous experiences developing reactive robots (but also I've gained more experience since then).
The process have involved designing not only the algorithms but to design a proper method, to design the tools -a simulation environment-, the experimental setup -the design and construction of the real robots and the image processing system for the robot positioning-, to design the experiments themselves and to analyze all the acquired data so it made sense.
The work line derived from the Thesis is still open for more research.
- The testing on real robots have been done in a controlled environment, but work is being done to test them in larger robots out of the lab, using GPS for localization, a magnetic compass for the robot orientation and range sensors / vision for the obstacle tracking.
- The studied tasks were focused on measure the reliability of the system, but more elements can be included: A simple memory scheme can be deployed in the form of a virtual field to avoid loop traps -any pure reactive method is exposed to them-. The description of the behaviours through their consequences is highly related with reinforced learning algorithms based on positive and negative rewards. To adapt the current implementation so the robot/robots follow a path instead of a straight line is trivial, it can easily be done with a virtual field.
And lot of other applications can be adapted, the Thesis just proposes a easy method to deploy a complex reactive system. - The reactive nature can also be employed to setup a system that combines different strategies, it have been suggested to be used in robot soccer.
- This reactive scheme can be easily combined with a high level path planner where the current method provides the reactive layer.
- Not only new applications can be explored, it will be quite interesting to explore the inclusion of more kinds of consequences, like considering several objectives or the conditioning between the different degrees of freedom of the robot.
- And, of course, the idea of describing the behaviours through the consequences of the actions is not restricted to the navigation, this same idea can be employed on other areas of robots. Any system which can benefit from a reactivity layer and uses expert knowledge can use this new description.
My own conclusion?. Along the Thesis I've not only gained experience and knowledge on robot navigation -which i have-.
Probably I've gained even more experience on how to deal with a problem. From the initial blurry ideas, the first research, testing alternative approaches, focusing the process and formalizing the steps, looking for the proper indicators and finally being able to do a solid enough collection of tests, validate them and being able to check them against the initial objectives.
The highest effort was not the research -which is quite fun-, it was to get a lot of initial blurry ideas into something that made sense.
The Real Robots

|

|
| Real robots developed for this Thesis. Two stepper motors, microcontroller -PIC18F4550- and radio link -MRF24J40MA-. | The red/blue patches at the top provides the means for the visual localization, the black&white strip between them provides a unique Id for each robot. |

|
|
Unprocessed frame used for robot tracking during the tests.
Two cameras were used to cover the experimental area. Positioning is done combining camera data and encoders through a Kalman filter. |
Simulation Environment

|
|
Simulation environment developed for this Thesis.
It handles both simulations and monitoring of the real tests. |
No hay comentarios:
Publicar un comentario